Understanding Statistical Metadata
What is Statistical Metadata?
Statistical metadata is information that describes, explains, locates, or otherwise makes it easier to retrieve, use, or manage statistical data. While the raw numbers constitute the data, metadata answers questions such as:
- Who produced the data and when?
- What methodology was used to collect and process it?
- What variables are included and how are they defined?
- What are the limitations, assumptions, and quality indicators?
In short, metadata provides the context needed to interpret statistical outputs correctly and to reuse them responsibly.
Main Types of Statistical Metadata
Statistical metadata can be grouped into several logical categories:
1. Descriptive Metadata
Basic identifying information such as title, abstract, keywords, geographic coverage, and time period.
2. Structural Metadata
Details about the organization of the dataset: file formats, table structures, variable names, and relationships between tables.
3. Administrative Metadata
Information used for managing the data: creation date, version, author, licensing, access rights, and provenance.
4. Process Metadata (Methodology)
Documentation of data collection methods, sampling design, weighting procedures, imputation techniques, and any transformations applied.
5. Quality Metadata
Indicators of data quality, including accuracy, completeness, consistency, timeliness, and any known errors or biases.
6. Referential Metadata
Links to related datasets, references to publications, and mappings to external standards (e.g., statistical classifications, code lists).
Why Statistical Metadata Matters
Without proper metadata, statistical data are often misunderstood, misused, or discarded. The main benefits are:
- Transparency: Stakeholders can see how numbers were derived.
- Reproducibility: Researchers can replicate analyses or build on existing work.
- Interoperability: Consistent metadata enable data from different sources to be combined.
- Discovery: Search engines and catalogues rely on metadata to index datasets.
- Compliance: Many legal frameworks (e.g., GDPR, open data mandates) require clear documentation.
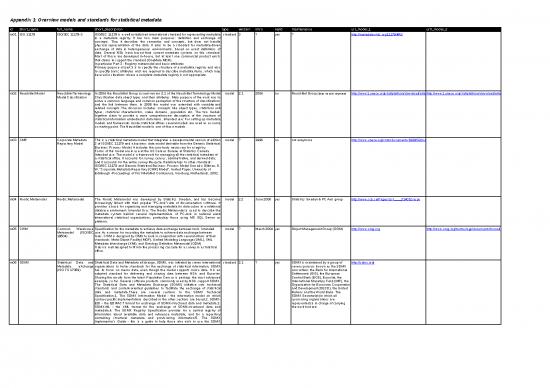
Key International Standards
Several organizations have developed specifications that promote uniformity and machinereadability:
| Standard | Scope | Primary Use |
|---|---|---|
| DDI (Data Documentation Initiative) | Social, behavioral, and health surveys | Metadata for microdata, questionnaires, and study-level information |
| SDMX (Statistical Data and Metadata eXchange) | Official statistics, macrodata | Exchange of data and metadata between agencies |
| DCAT (Data Catalog Vocabulary) | Open data portals | Dataset discovery and cataloguing |
| ISO 19115 (Geographic information) | Spatial statistics | Metadata for geographic datasets |
Adopting one or more of these standards improves both human readability and automated processing.
Best Practices for Creation & Management
- Plan metadata from the start treat it as a deliverable, not an afterthought.
- Use controlled vocabularies ISO codes, UN statistical classifications, or domainspecific lists reduce ambiguity.
- Separate metadata from data store metadata in machinereadable formats (XML, JSON, RDF) alongside the dataset.
- Version everything each release of data and its metadata should carry a unique version identifier.
- Document methodological choices describe sampling frames, weighting, imputation, and any data cleaning steps.
- Provide quality statements include error margins, response rates, and known limitations.
- Assign persistent identifiers DOIs or Handles make datasets citable and traceable.
- Publish openly share metadata under a clear license; consider openmetadata portals.
- Validate regularly use schema validation tools to ensure compliance with chosen standards.
Tools and Platforms
A range of free and commercial solutions help organisations create, manage, and expose statistical metadata:
- Metadata Editors: DDI Codebook, Colectica, and the Open Metadata Registry (OMR) provide guided interfaces for DDI and DCAT.
- Data Portals: CKAN, Socrata, and the European Data Portal natively support DCATAP and SDMX.
- Validation: XML Schema Definition (XSD) validators, JSON Schema tools, and the metadatavalidator library for DDI.
- Automation: Scripts in R (package
ddic) or Python (librarypySDMX) can generate metadata from codebooks.
Common Challenges
Even with standards, practitioners encounter obstacles:
- Resource constraints detailed metadata creation can be timeintensive.
- Inconsistent terminology legacy datasets may use local jargon that conflicts with global vocabularies.
- Version drift metadata may fall out of sync with the underlying data after updates.
- Balancing detail and usability too much technical information can overwhelm nonexpert users.
Addressing these issues typically involves establishing clear governance policies and investing in staff training.
Future Directions
Emerging trends promise to enhance the role of statistical metadata:
- Linked Open Data Expressing metadata as RDF triples enables richer connections across datasets.
- Machinegenerated metadata AI tools can automatically extract variable definitions from questionnaires or codebooks.
- Dynamic metadata Realtime updates for streaming data sources, supported by APIs like the SDMX RESTful service.
- Privacyaware metadata Embedding privacy impact assessments directly in the metadata to support responsible data sharing.
Adopting these innovations will make statistical data more transparent, interoperable, and trustworthy.
For more information, visit the DDI Alliance, the SDMX Initiative, or explore the DCAT specification.